How to diff XML
Lennart Regebro
Plone Conf 2018, Tokyo
Shoobx is the only comprehensive platform for incorporation, employee onboarding, equity management, fundraising, board & stockholder communication, and more.

SBT + magic = PDF



xmldiff 0.6

The output was no good
There was a memory leak in the C code
My C coding skills are rusty
It was hard to maintain
And some infinite loop somewhere
And it was really hard to improve the matching
xmldiff (again!)
Almost entirely incompatible
Pure-python
Better results
Easier to use as a library
Supports writing formatters!
How do you diff?
Match
Edit
Output
Matching
Longest Common Subsequence
Old: 1 2 3 4 5 6 7 8
New: 1 2 9 4 6 5 7 7
LCS: 1 2 4 6 7
Editing
Delete 3 Insert 9 at position 3 Delete 5 Insert 5 at position 6 Delete 8 Insert 7 at position 8
Output
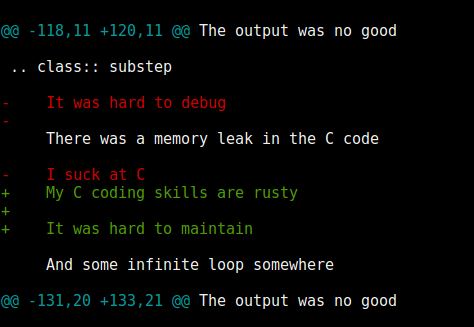
Matching XML
<para section="3"> <b>3. </b>Lorem ipsum have some gypsum </para>
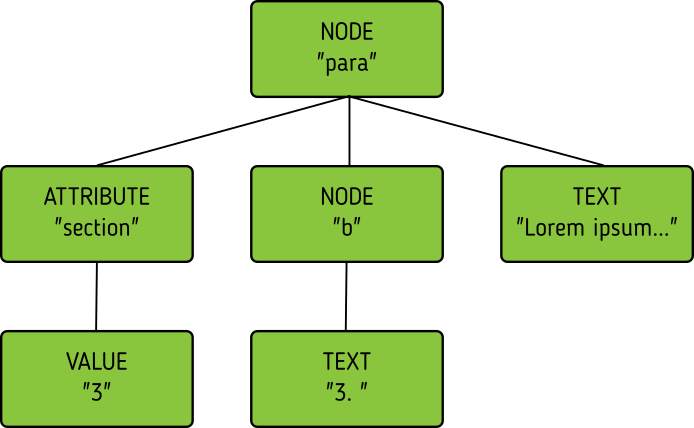
A new version
<para section="4"> <b>4. </b>Lorem ipsum have some gypsum </para>
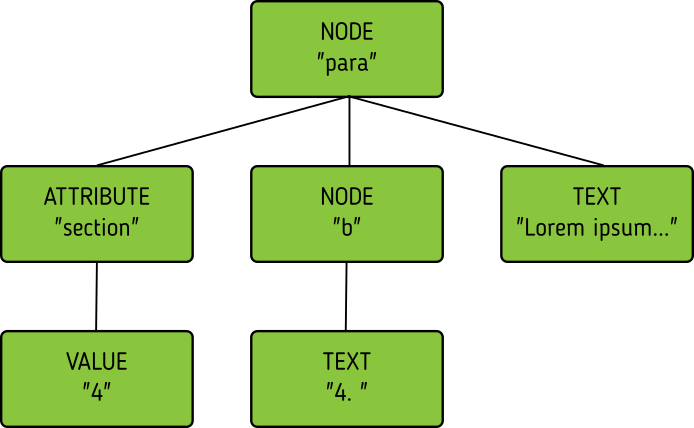
No match!
<para section="4"> <b>4. </b>Lorem ipsum have some gypsum </para>
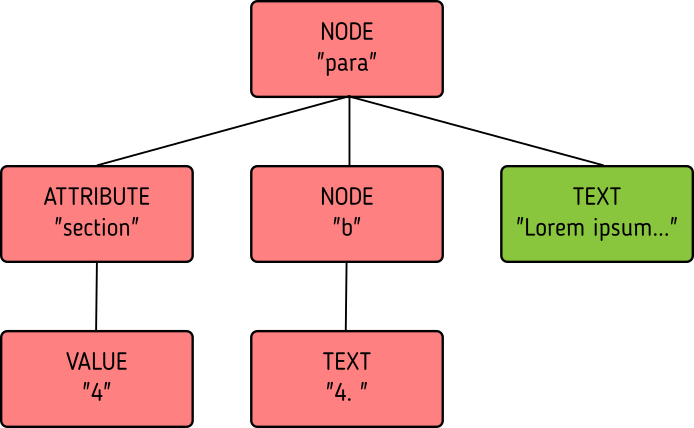
Node:
<para section="3"> <b>3. </b>Lorem ipsum have some gypsum </para>
Value:
"section:3 Lorem ipsum have some gypsum"
Matching procedure: LCS?
Fast, bad matching
Compare all nodes to all nodes
Nightmarishly slow
Single-iteration best match
Good enough!
XML edit actions
DeleteNode, InsertNode, RenameNode, MoveNode
DeleteAttrib, InsertAttrib, RenameAttrib, UpdateAttrib
UpdateTextIn, UpdateTextAfter
InsertComment
Making the edit script
Walk the "new" tree, node by node.
If it has a match, look for differences.
If there is no match, insert it!
Delete all nodes from the old tree with no match.
Generate output
[update-attribute, /para[1], section, "4"] [update-text, /para/b[1], "4. "]
End Result
<para section="4" class="modified"> <b><span class="delete">3</span> <span class="insert">4</span>. </b> Lorem ipsum have some gypsum </para>
XML Output
<para section="4" diff:update-attr="section:3"> <b><diff:delete>3</diff:delete> <diff:insert>4</diff:insert>. </b> Lorem ipsum have some gypsum </para>
XSLT gotcha
<app:term name="expenses" set="advisor" allowCustom="True"> <app:option name="bear_own"> <whatever/> </app:option> <app:option name="reimburse"> <blahblah/> </app:option> </app:term>
<xsl:value-of select="sbx:getFieldTitle($content-expr)" />
<asection name="expenses" allowCustom="True" diff:rename="app:term" diff:delete-attr="set"> <whatever diff:delete="" diff:insert="" /> <app:option name="bear_own" diff:delete=""> </app:option> <blahblah diff:delete="" diff:insert="" /> <app:option name="reimburse" diff:delete=""> </app:option> </app:term>
Formatted text
Old:
<p>This is formatted text</p>
New:
<p>This <b>is</b> formatted <i>text</i></p>
Unicode stubs
<p>This \ue000is\ue001 text that can have \ue002formatting\ue003</p>
Unicode stubs
<p>This <b diff:insert="">text</b> that can have <i diff:insert="">formatting</i></p>
Soooo slooow
Stop looking when you find perfection
Use faster algorithms from difflib
Implement the LCS "fast-match" algorithm
Caching
Harder, Better, Faster, Stronger
xmldiff 0.6: 8 seconds
xmldiff 2.0: 100 seconds
xmldiff 2.1: 5 seconds
With faster ratio-mode: 2 seconds
With fast-match: 1.5 seconds
How can YOU use it?
>>> from xmldiff import main >>> main.diff_files( ... "../tests/test_data/insert-node.left.html", ... "../tests/test_data/insert-node.right.html") [UpdateTextIn(node='/body/div[1]', text=None), InsertNode(target='/body/div[1]', tag='p', position=0), UpdateTextIn(node='/body/div/p[1]', text='Simple text')]
XML Output
>>> from xmldiff import formatting
>>> formatter = formatting.XMLFormatter(
... text_tags=['p'], formatting_tags=['i', 'b'])
>>> main.diff_files(
... "../tests/test_data/insert-node.left.html",
... "../tests/test_data/insert-node.right.html",
... formatter=formatter)
<body xmlns:diff="http://namespaces.shoobx.com/diff">
<div id="id">
<p diff:insert="">Simple text</p>
</div>
</body>Future
We ain't stopping now!
